
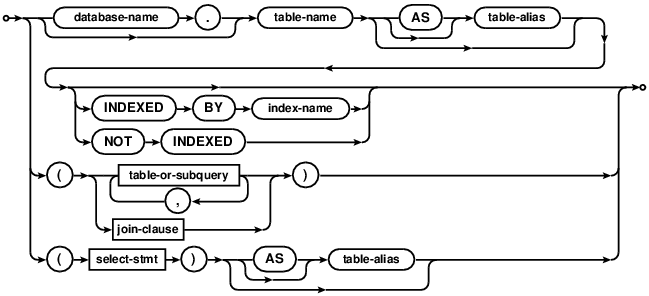
Choose any three.
|
|
SQLite里的SQL
SQL As Understood By SQLite
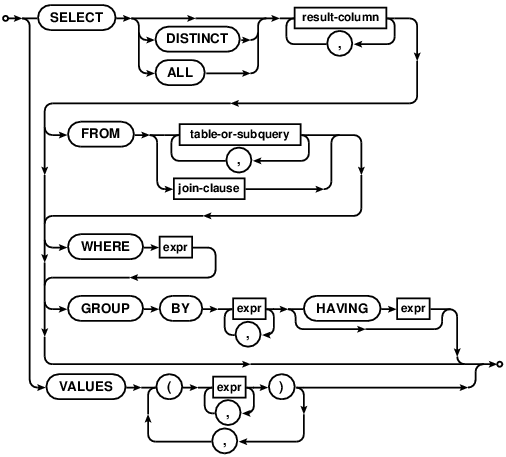
SELECT


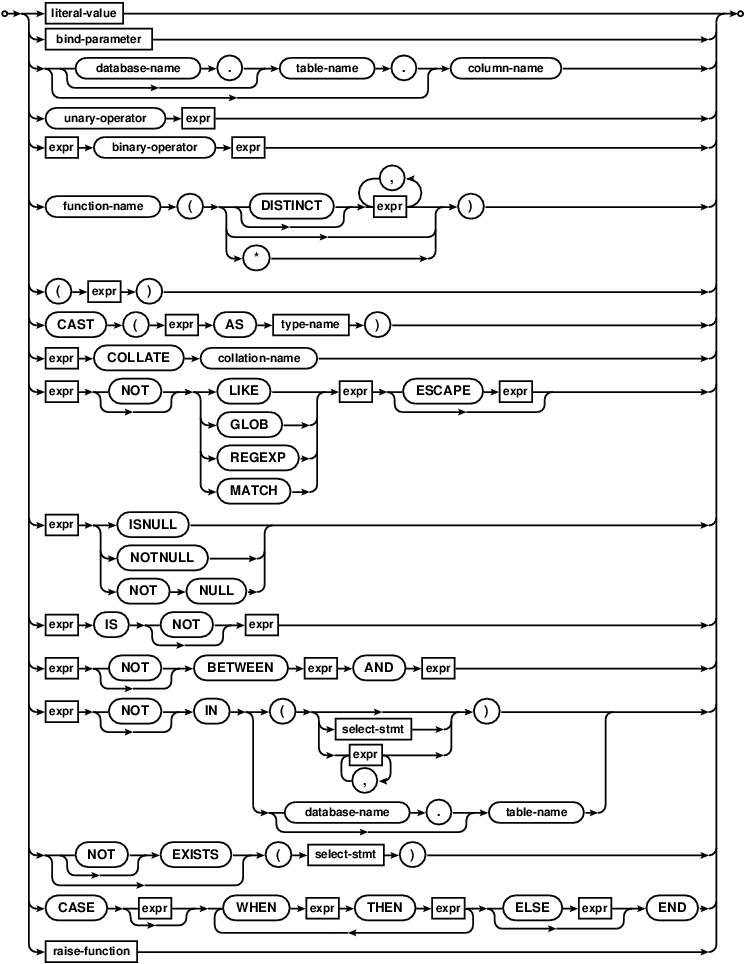



SELECT语句是用来查询数据库的。SELECT返回的结果为零或多行固定列数的数据。SELECT语句不会对数据库做任何修改。
The SELECT statement is used to query the database. The
result of a SELECT is zero or more rows of data where each row
has a fixed number of columns. A SELECT statement does not make
any changes to the database.
上面的 "select-stmt"语法图试图在一张图里展示尽可能多的SELECT语法,这是因为很多读者认为这个图非常有帮助。接下来的 "factored-select-stmt"表达了同样的语法,与上图不同的是,将上面的语法图拆分成了多个较小的语法块。
The "select-stmt" syntax diagram above attempts to show as much of the
SELECT statement syntax as possible in a single diagram, because some readers
find that helpful. The following "factored-select-stmt" is an alternative
syntax diagrams that expresses the same syntax but tries to break the syntax
down into smaller chunks.
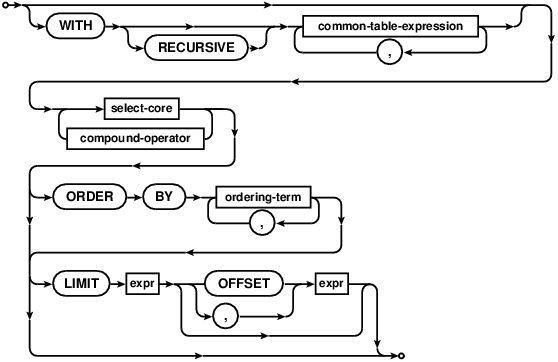
注意语法图中有一些语法路径在实际中是不允许的,例如:
Note that there are paths through the syntax diagrams that
are not allowed in practice. Some examples:
- 在一个使用了WITH子句的复合 SELECT语句中VALUES可以作为第一个元素,但是只包含一个VALUES子句的简单 SELECT语句前面则不能使用WITH子句。
A VALUES clause can be the first element in a compound SELECT that uses a WITH clause, but a simple SELECT that consists of just a VALUES clause cannot be preceded by a WITH clause. - WITH子句只能出现在复合 SELECT语句中的第一个SELECT之前。不能跟随在compound-operator之后。
The WITH clause must occur on the first SELECT of a compound SELECT. It cannot follow a compound-operator.
These and other similar syntax restrictions are described in the text.
SELECT语句是SQL语言中最复杂的命令。为了使描述更易于理解,下面的一些短文通过将决定SELECT语句返回什么数据的逻辑分解为多个步奏的方式来讲解。需要特别明确的是,这么做只是纯粹为了说明理解,在实际使用中,无论SQLite还是其他SQL引擎都不会要求必须使用这样的流程活着其它特殊的流程。
The SELECT statement is the most complicated command in the SQL language.
To make the description easier to follow, some of the passages below describe
the way the data returned by a SELECT statement is determined as a series of
steps. It is important to keep in mind that this is purely illustrative -
in practice neither SQLite nor any other SQL engine is required to follow
this or any other specific process.
简单SELECT处理
Simple Select Processing
"简单 SELECT" 是SELECT语句的核心内容,下面的select-core 和 simple-select-stmt语法图展示了 "简单 SELECT"的内容。在实际使用中,大多数的SELECT语句都是简单SELECT语句。
The core of a SELECT statement is a "simple SELECT" shown by the
select-core and simple-select-stmt syntax diagrams below.
In practice, most SELECT statements are simple SELECT statements.
下面分四个步奏来介绍一条简单SELECT语句是如何生成结果的。
Generating the results of a simple SELECT
statement is presented as a four step process in the description below:
-
FROM 子句过程:决定简单SELECT语句的输入数据。输入数据既可以是默认的一行零列的数据(如果没有FROM子句)也可以由FROM子句来指定。
FROM clause processing: The input data for the simple SELECT is determined. The input data is either implicitly a single row with 0 columns (if there is no FROM clause) or is determined by the FROM clause. -
WHERE 子句过程:使用WHERE子句表达式来过滤数据。
WHERE clause processing: The input data is filtered using the WHERE clause expression. -
GROUP BY, HAVING and result-column 表达式过程: 计算结果集中的每一行数据还需要依照GROUP BY子句来聚合数据和为过滤后的输入数据集计算结果集表达式。
GROUP BY, HAVING and result-column expression processing: The set of result rows is computed by aggregating the data according to any GROUP BY clause and calculating the result-set expressions for the rows of the filtered input dataset. -
DISTINCT/ALL 关键词过程:如果查询语句是一条"SELECT DISTINCT"查询,那么重复的行会从结果集中去除。
DISTINCT/ALL keyword processing: If the query is a "SELECT DISTINCT" query, duplicate rows are removed from the set of result rows.
简单SELECT语句包含两种类型——聚合查询和非聚合查询。如果一个简单SELECT语句包含GROUP BY子句,或者在结果集中使用了一个以上的聚合函数,那么这就是一个聚合查询。相反,如果一个简单SELECT语句不包含GROUP BY子句和聚合函数,那么就是一个非聚合函数。
There are two types of simple SELECT statement - aggregate and
non-aggregate queries. A simple SELECT statement is an aggregate query if
it contains either a GROUP BY clause or one or more aggregate functions
in the result-set. Otherwise, if a simple SELECT contains no aggregate
functions or a GROUP BY clause, it is a non-aggregate query.
1. 指定输入数据(FROM子句过程)
1. Determination of input data (FROM clause processing).
简单SELECT查询使用的输入数据就是一个N行,每行M列的集合。
The input data used by a simple SELECT query is a set of N rows
each M columns wide.
如果简单SELECT语句中省略了FROM子句,那么就暗示输入数据是一个一行零列的数据(N=1,
M=0)。
If the FROM clause is omitted from a simple SELECT statement, then the
input data is implicitly a single row zero columns wide (i.e. N=1 and
M=0).
如果指定了FROM子句,那么简单SELECT查询操作的输入数据则来自于跟随在FROM关键字后面的一张或多张表或者子查询(圆括号内的SELECT语句)。简单SELECT语句中FROM后面指定的子查询会被当做一个包含子查询语句计算结果的表来使用。子查询中的每一列都根据子查询语句中对应的表达式推算出排序器 和 类型亲和力。
If a FROM clause is specified, the data on which a simple SELECT query
operates comes from the one or more tables or subqueries (SELECT statements
in parenthesis) specified following the FROM keyword. A subquery specified
in the table-or-subquery following the FROM clause in a
simple SELECT statement is
handled as if it was a table containing the data returned by executing the
subquery statement. Each column of the subquery has the
collation sequence and affinity of the corresponding expression
in the subquery statement.
如果FROM子句中只有一张表或者一个子查询,那么SELECT语句使用的输入数据就是这个表的内容或者子查询的结果。如果FROM子句中包含超过一张表或者一个子查询,那么SELECT语句操作的输入数据就是所有的表和子查询的内容连接在一起生成的一个单独的大数据集。join-operator 和
join-constraint准确介绍了如何将表和子查询中的数据结合到一起。
If there is only a single table or subquery in the FROM
clause, then the input data used by the SELECT statement is the contents of the
named table. If there is more than one table or subquery in FROM clause
then the contents of all tables and/or subqueries
are joined into a single dataset for the simple SELECT statement to operate on.
Exactly how the data is combined depends on the specific join-operator and
join-constraint used to connect the tables or subqueries together.
SQLite中的所有连接操作都是以左侧或右侧数据集的笛卡尔积为基础的。笛卡尔积数据集中的列是由左边数据集的所有列和右边数据集的所有列按顺序排列在一起组成的。笛卡尔积数据集中的行是由左右两边数据集中每一行的不同组合组成的。换句话说,如果左边数据集包含Nleft 行Mleft列,右边数据集包含Nright 行Mright列,那么笛卡尔积数据集则包含Nleft×Nright行,每行包含Mleft+Mright列。
All joins in SQLite are based on the cartesian product of the left and
right-hand datasets. The columns of the cartesian product dataset are, in
order, all the columns of the left-hand dataset followed by all the columns
of the right-hand dataset. There is a row in the cartesian product dataset
formed by combining each unique combination of a row from the left-hand
and right-hand datasets. In other words, if the left-hand dataset consists of
Nleft rows of
Mleft columns, and the right-hand dataset of
Nright rows of
Mright columns, then the cartesian product is a
dataset of
Nleft×Nright
rows, each containing
Mleft+Mright columns.
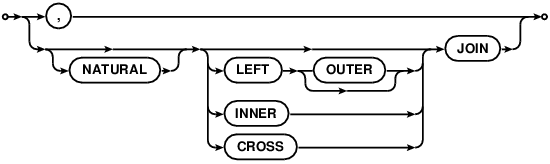
如果连接操作符是"CROSS JOIN", "INNER JOIN", "JOIN" 或者一个逗号
(",")并且没有ON或者USING子句,那么连接的结果就是左右两边数据集的简单笛卡尔积。如果连接操作符包含ON或USING子句,那么会按照下面这些情况来处理:
If the join-operator is "CROSS JOIN", "INNER JOIN", "JOIN" or a comma
(",") and there is no ON or USING clause, then the result of the join is
simply the cartesian product of the left and right-hand datasets.
If join-operator does have ON or USING clauses, those are handled according to
the following bullet points:
-
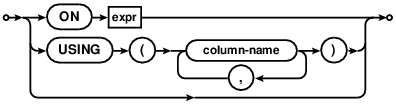
如果包含一个ON子句,那么将笛卡尔积的每一行传入ON后面的布尔表达式进行运算,只有返回的true的行才会进入到数据集中。
If there is an ON clause then the ON expression is evaluated for each row of the cartesian product as a boolean expression. Only rows for which the expression evaluates to true are included from the dataset. -
如果包含一个USING子句,那么指定的每一个列名都必须是连接操作符左右两边数据集都含有的。每一对指定的列都会使用一个 "lhs.X = rhs.X"的布尔表达式对笛卡尔积的每一行进行运算。只有每个表达式都返回true的行才会进入到结果集中。在对USING子句的结果进行比较时,处理亲和性、排序器和NULL值都适用一般规则。位于连接符左边的数据集的列的排序器和亲和性优先与右边的。
If there is a USING clause then each of the column names specified must exist in the datasets to both the left and right of the join-operator. For each pair of named columns, the expression "lhs.X = rhs.X" is evaluated for each row of the cartesian product as a boolean expression. Only rows for which all such expressions evaluates to true are included from the result set. When comparing values as a result of a USING clause, the normal rules for handling affinities, collation sequences and NULL values in comparisons apply. The column from the dataset on the left-hand side of the join-operator is considered to be on the left-hand side of the comparison operator (=) for the purposes of collation sequence and affinity precedence.对于每对USING子句指定的列右边数据集的那一列在连接结果集中会被省略掉。这也是USING子句与等价的ON约束唯一不同的地方。
For each pair of columns identified by a USING clause, the column from the right-hand dataset is omitted from the joined dataset. This is the only difference between a USING clause and its equivalent ON constraint. -
如果在连接操作符中适用NATURAL关键词,那么就意味着隐式使用了USING子句作为连接约束。USING子句包含了每一个同时出现在左右两边输入数据集的列名。如果左右两边输入数据集没有相同的列名,那么NATURAL关键词就不会对连接结果集产生影响。在指定了NATURAL关键词的连接操作中不应该再使用USING或者ON子句了。
If the NATURAL keyword is in the join-operator then an implicit USING clause is added to the join-constraints. The implicit USING clause contains each of the column names that appear in both the left and right-hand input datasets. If the left and right-hand input datasets feature no common column names, then the NATURAL keyword has no effect on the results of the join. A USING or ON clause may not be added to a join that specifies the NATURAL keyword. -
如果连接操作符是"LEFT JOIN" 或者 "LEFT OUTER JOIN",那么在处理完ON或USING过滤子句后,左边输入数据集中如果存在没有进入最终复合结果集的行会被加入到输出数据集中。这些额外的行中,那些本应该填入右边输入集对应列值的列被填入了NULL值。
If the join-operator is a "LEFT JOIN" or "LEFT OUTER JOIN", then after the ON or USING filtering clauses have been applied, an extra row is added to the output for each row in the original left-hand input dataset that corresponds to no rows at all in the composite dataset (if any). The added rows contain NULL values in the columns that would normally contain values copied from the right-hand input dataset.
当FROM子句中需要将两个以上的表连接到一起时,连接操作符会按照从左往右依次操作。换句话说,FROM子句(A join-op-1 B join-op-2 C)会被按照((A join-op-1 B) join-op-2 C)来计算。
When more than two tables are joined together as part of a FROM clause,
the join operations are processed in order from left to right. In other
words, the FROM clause (A join-op-1 B join-op-2 C) is computed as
((A join-op-1 B) join-op-2 C).
旁注:CROSS JOIN的特殊处理。"INNER JOIN", "JOIN" 和 ","连接符之间是没有区别的,在SQLite中是完全可以进行互换的。"CROSS JOIN"连接操作可以产生与"INNER JOIN", "JOIN" 和 ","连接符相同的结果,但是在查询优化器处理上有所不同,它会阻止查询优化器在连接表时重排表。应用程序开发者可以使用CROSS JOIN操作来直接影响SELECT语句的实现算法的选择。除非希望人工控制查询优化器,否则应该避免使用CROSS JOIN。应该在应用开发初期避免使用CROSS JOIN,因为这是过早优化的行为。对CROSS JOIN的特殊处理只是SQLite的一个特性,而不是SQL标准规范中规定的。
Side note: Special handling of CROSS JOIN.
There is no difference between the "INNER JOIN", "JOIN" and "," join
operators. They are completely interchangeable in SQLite.
The "CROSS JOIN" join operator produces the same result as the
"INNER JOIN", "JOIN" and "," operators, but is
handled differently by the query optimizer
in that it prevents the query optimizer from reordering
the tables in the join. An application programmer can use the CROSS JOIN
operator to directly influence the algorithm that is chosen to implement
the SELECT statement. Avoid using CROSS JOIN except in specific situations
where manual control of the query optimizer is desired. Avoid using
CROSS JOIN early in the development of an application as doing so is
a premature
optimization. The special handling of CROSS JOIN is an SQLite-specific
feature and is not a part of standard SQL.
2.WHERE子句过滤
2. WHERE clause filtering.
如果制定了WHERE子句,那么WHERE表达式会作为一个布尔表达式对输入数据的每一行进行计算。只有当WHERE子句表达式计算结果为true的行才会被包含进后续处理的数据集中,WHERE子句计算结果为NULL活着false的行会从结果中排除出去。
If a WHERE clause is specified, the WHERE expression is evaluated for
each row in the input data as a boolean expression. Only rows for which the
WHERE clause expression evaluates to true are included from the dataset before
continuing. Rows are excluded from the result if the WHERE clause
evaluates to either false or NULL.
对于JOIN、INNER JOIN和CROSS JOIN来说,WHERE子句中的约束表达式和ON子句中的表达式是没有区别的。可是对于LEFT JOIN 和LEFT OUTER JOIN来说区别就非常大了。在LEFT JOIN中,为右边表格插入额外NULL行的操作是发生在ON子句处理之后的,但是实在WHERE子句之前。在ON子句中"left.x=right.y"这种形式的约束会允许右边表格对应列填入NULL的额外行进入结果集。但是如果在WHERE子句中有同样的约束,那么"right.y"中的NULL值会使表达式 "left.x=right.y"返回false,从而将这些额外的行从结果中排除。
For a JOIN or INNER JOIN or CROSS JOIN, there is no difference between
a constraint expression in the WHERE clause and one in the ON clause. However,
for a LEFT JOIN or LEFT OUTER JOIN, the difference is very important.
In a LEFT JOIN,
the extra NULL row for the right-hand table is added after ON clause processing
but before WHERE clause processing. A constraint of the form "left.x=right.y"
in an ON clause will therefore allow through the added all-NULL rows of the
right table. But if that same constraint is in the WHERE clause a NULL in
"right.y" will prevent the expression "left.x=right.y" from being true, and
thus exclude that row from the output.
3.生成结果集
3. Generation of the set of result rows.
一旦来自FROM子句的数据通过了WHERE子句表达式的过滤,简单SELECT的结果集就会被计算出来了,具体如何计算决定于简单SELECT是一个聚合查询还是非聚合查询,是否指定了GROUP BY子句。
Once the input data from the FROM clause has been filtered by the
WHERE clause expression (if any), the set of result rows for the simple
SELECT are calculated. Exactly how this is done depends on whether the simple
SELECT is an aggregate or non-aggregate query, and whether or not a GROUP
BY clause was specified.
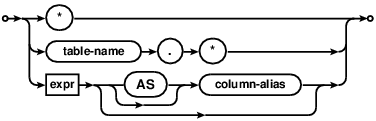
在SELECT和FROM关键词之间的表达式列表被称为结果表达式列表。如果结果表达式是特殊表达式"*"那么会以输入数据中的所有列替代这个表达式。如果表达式是一个FROM子句中的表或者子查询的别名加上".*"后缀,那么会以名字指定的表或者子查询的所有列替代这个单独的表达式。在除了结果表达式列表以外的任何上下文环境中使用"*"和"alias.*"都会导致错误。在一个没有FROM子句的简单SELECT语句的结果表达式列表中使用"*"和"alias.*"也同样会导致错误。
The list of expressions between the SELECT and FROM keywords is known as
the result expression list. If a result expression is the special expression
"*" then all columns in the input data are substituted for that one expression.
If the expression is the alias of a table or subquery in the FROM clause
followed by ".*" then all columns from the named table or subquery are
substituted for the single expression. It is an error to use a "*" or
"alias.*" expression in any context other than a result expression list.
It is also an error to use a "*" or "alias.*" expression in a simple SELECT
query that does not have a FROM clause.
简单SELECT语句返回的结果行中的列数与结果表达式列表替换完*和alias.*之后的表达式个数相同。结果的每行数据都是输入数据中的每行数据经过结果表达式列表的计算得出的,如果是一个聚合查询,那么结果对应的是一组行的计算结果。
The number of columns in the rows returned by a simple SELECT statement
is equal to the number of expressions in the result expression list after
substitution of * and alias.* expressions. Each result row is calculated by
evaluating the expressions in the result expression list with respect to a
single row of input data or, for aggregate queries, with respect to a group
of rows.
如果SELECT语句是一个非聚合查询,那么经过WHERE子句过滤后的数据集的每一行都要经过结果表达式列表中的每个表达式的计算。
If the SELECT statement is a non-aggregate query, then each expression in the result expression list is evaluated for each row in the dataset filtered by the WHERE clause.如果SELECT语句是一个不包含GROUP BY的聚合查询,那么结果表达式列表里的每个聚合表达式都要计算整个数据集的数据。结果表达式列表中的每个非聚合表达式都是会对数据集中随机一行的数据进行一次计算。每个非聚合表达式都使用的是同一行随机数据记录。如果数据集一行数据都没有,那么每个非聚合表达式都会针对一个每列都是NULL值的行进行计算。
If the SELECT statement is an aggregate query without a GROUP BY clause, then each aggregate expression in the result-set is evaluated once across the entire dataset. Each non-aggregate expression in the result-set is evaluated once for an arbitrarily selected row of the dataset. The same arbitrarily selected row is used for each non-aggregate expression. Or, if the dataset contains zero rows, then each non-aggregate expression is evaluated against a row consisting entirely of NULL values.一个没有GROUP BY子句的聚合查询的结果集中唯一的一行数据是由结果表达式列表中的聚合表达式和非聚合表达式的计算结果组成的。一个没有GROUP BY子句的聚合函数总是会返回唯一一行数据结果,哪怕输入数据是零行。
The single row of result-set data created by evaluating the aggregate and non-aggregate expressions in the result-set forms the result of an aggregate query without a GROUP BY clause. An aggregate query without a GROUP BY clause always returns exactly one row of data, even if there are zero rows of input data.如果SELECT语句是一个包含GROUP BY子句的聚合查询那么GROUP BY子句中指定的每一个表达式都会对数据集的每一行进行计算。这时数据集的每一行都会依照表达式结果分配到一个"组"里;GROUP BY表达式计算结果相同的数据行会被分配到同一个组里。为了聚合成组,所有的NULL值会被认为是相同的。在计算GROUP BY子句中的表达式时,依照通常的 选择一个排序器的规则选在一个排序器进行文本比较。GROUP BY子句中的表达式并不一定会出现在结果表达式中GROUP BY子句中的表达式不一定是一个聚合表达式。
If the SELECT statement is an aggregate query with a GROUP BY clause, then each of the expressions specified as part of the GROUP BY clause is evaluated for each row of the dataset. Each row is then assigned to a "group" based on the results; rows for which the results of evaluating the GROUP BY expressions are the same get assigned to the same group. For the purposes of grouping rows, NULL values are considered equal. The usual rules for selecting a collation sequence with which to compare text values apply when evaluating expressions in a GROUP BY clause. The expressions in the GROUP BY clause do not have to be expressions that appear in the result. The expressions in a GROUP BY clause may not be aggregate expressions.如果指定了HAVING子句,子句中的布尔表达式会对每一组行计算一次。如果HAVING子句表达式的计算结果为false,那么这一组行就会被丢弃。如果HAVING子句是一个聚合表达式,那么会计算一组内的每一行记录。如果HAVING子句是一个非聚合表达式,那么会对一组行中的随机一行进行计算。HAVING表达式中可以使用结果中没有的的值或者聚合函数。
If a HAVING clause is specified, it is evaluated once for each group of rows as a boolean expression. If the result of evaluating the HAVING clause is false, the group is discarded. If the HAVING clause is an aggregate expression, it is evaluated across all rows in the group. If a HAVING clause is a non-aggregate expression, it is evaluated with respect to an arbitrarily selected row from the group. The HAVING expression may refer to values, even aggregate functions, that are not in the result.这时,结果表达式列表中的每个表达式会对每组数据进行一次计算。如果是一个聚合表达式,那么会对组里的所有行记录进行计算,否则会从每组数据中随机选择一行数据进行计算。如果包含多个非聚合表达式,则所有表达式都是对同一行数据进行计算。
Each expression in the result-set is then evaluated once for each group of rows. If the expression is an aggregate expression, it is evaluated across all rows in the group. Otherwise, it is evaluated against a single arbitrarily chosen row from within the group. If there is more than one non-aggregate expression in the result-set, then all such expressions are evaluated for the same row.在结果集中,每组输入数据会输出一行记录。在使用聚合函数和GROUP BY子句生成的结果集上使用DISTINCT关键字来过滤相同的列项目,最终得出的结果行数与使用GROUP BY 和HAVING子句过滤输入数据后的组数是一样的。(没有理解,翻译的应该有问题,后续再重新翻译#TODO#)
Each group of input dataset rows contributes a single row to the set of result rows. Subject to filtering associated with the DISTINCT keyword, the number of rows returned by an aggregate query with a GROUP BY clause is the same as the number of groups of rows produced by applying the GROUP BY and HAVING clauses to the filtered input dataset.
4.移除重复行(DISTINCT处理)。
4. Removal of duplicate rows (DISTINCT processing).
在简单SELECT语句中SELECT关键词后可以跟随一个ALL或者DISTINCT关键词。如果简单SELECT是一个SELECT ALL,那么SELECT会返回所有的结果行。如果既没有指定ALL也没有指定DISTINCT,那么会默认指定ALL。如果简单SELECT是一个SELECT DISTINCT,那么会在结果集返回之前去处结果集中重复的行。为了检查重复行,两个NULL值会被认为相等。会按照通常规则来选择一个排序器进行字符比较。
One of the ALL or DISTINCT keywords may follow the SELECT keyword in a
simple SELECT statement. If the simple SELECT is a SELECT ALL, then the
entire set of result rows are returned by the SELECT. If neither ALL or
DISTINCT are present, then the behavior is as if ALL were specified.
If the simple SELECT is a SELECT DISTINCT, then duplicate rows are removed
from the set of result rows before it is returned. For the purposes of
detecting duplicate rows, two NULL values are considered to be equal. The
normal rules for selecting a collation sequence to compare text values with
apply.
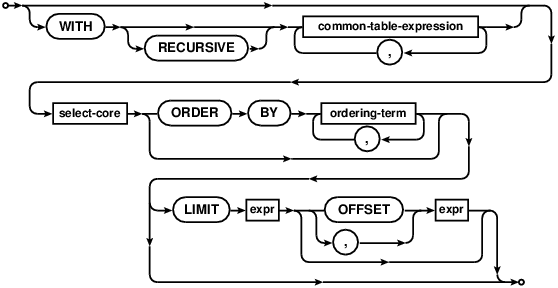
复合SELECT语句
Compound Select Statements
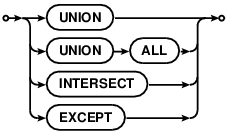
可以使用UNION、 UNION ALL、 INTERSECT 或 EXCEPT 操作符将两个以上的简单 SELECT语句连接到一起构成一个复合SELECT。如下面的语法图:
Two or more simple SELECT statements may be connected together to form
a compound SELECT using the UNION, UNION ALL, INTERSECT or EXCEPT operator,
as shown by the following diagram:
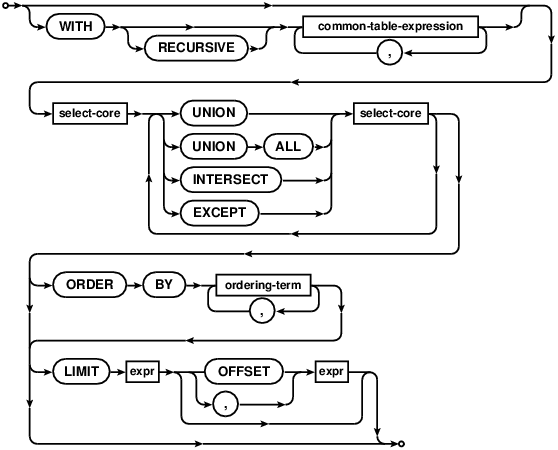
在复合SELECT中,所有的SELECT成员都必须返回相同列数的结果。复合SELECT的组件必须是一个简单SELECT,且不能包含ORDER BY 或 LIMIT子句。ORDER BY 和 LIMIT子句只能出现在整个复合SELECT的末尾处,并且要求复合的最后一个元素不能是VALUES子句。
In a compound SELECT, all the constituent SELECTs must return the same
number of result columns. As the components of a compound SELECT must
be simple SELECT statements, they may not contain ORDER BY or LIMIT clauses.
ORDER BY and LIMIT clauses may only occur at the end of the entire compound
SELECT, and then only if the final element of the compound is not a VALUES clause.
使用UNION ALL创建的复合SELECT会返回UNION ALL左边的SELECT的所有结果行和右边的SELECT的所有行。UNION操作符除了会在最终结果集中去处相同行外,其他与UNION ALL相同。INTERSECT操作符会返回左右两边SELECT结果集的交集。EXCEPT操作符会返回左边SELECT结果集中没有在右边SELECT结果集中出现的行记录。INTERSECT 和 EXECPT操作符都会在返回前去除结果集中的重复行。
A compound SELECT created using UNION ALL operator returns all the rows
from the SELECT to the left of the UNION ALL operator, and all the rows
from the SELECT to the right of it. The UNION operator works the same way as
UNION ALL, except that duplicate rows are removed from the final result set.
The INTERSECT operator returns the intersection of the results of the left and
right SELECTs. The EXCEPT operator returns the subset of rows returned by the
left SELECT that are not also returned by the right-hand SELECT. Duplicate
rows are removed from the results of INTERSECT and EXCEPT operators before the
result set is returned.
为了确定复合SELECT的结果集中的重复行,所有的NULL值会被当做相同值,且与其他非NULL值不同。选择用来比较两个文本的排序器如同左右两边SELECT语句的列在等号(=)两边一样,除非后缀一个COLLATE操作符来指定最高优先级的排序器。在复合SELECT中比较行时不会发生亲和力转换。
For the purposes of determining duplicate rows for the results of compound
SELECT operators, NULL values are considered equal to other NULL values and
distinct from all non-NULL values. The collation sequence used to compare
two text values is determined as if the columns of the left and right-hand
SELECT statements were the left and right-hand operands of the equals (=)
operator, except that greater precedence is not assigned to a collation
sequence specified with the postfix COLLATE operator. No affinity
transformations are applied to any values when comparing rows as part of a
compound SELECT.
当一个复合SELECT需要连接三个以上的简单SELECT时,会从左到右分组。换句话说如果"A"、 "B" 和 "C"都是简单SELECT语句, (A op B op C) 会按照 ((A op B) op C)来处理。
When three or more simple SELECTs are connected into a compound SELECT,
they group from left to right. In other words, if "A", "B" and "C" are all
simple SELECT statements, (A op B op C) is processed as ((A op B) op C).
ORDER BY 子句
The ORDER BY clause
如果一个返回多行记录的SELECT语句没有使用ORDER BY子句,那么返回行的顺序就是未定义的。相反,如果一个SELECT语句包含了一个ORDER BY 子句,那么按照ORDER BY后跟随的表达式来决定返回给用户的顺序。
If a SELECT statement that returns more than one row does not have an
ORDER BY clause, the order in which the rows are returned is undefined.
Or, if a SELECT statement does have an ORDER BY clause, then the list of
expressions attached to the ORDER BY determine the order in which rows
are returned to the user.
在一个复合 SELECT语句中,只有最右边的简单 SELECT可以包含一个ORDER BY子句,这个ORDER BY子句可以对复合的所有元素进行排序。如果复合 SELECT的最右边的元素是一个VALUES子句,那么这个语句中不允许使用ORDER BY子句。
In a compound SELECT statement, only the last or right-most simple SELECT
may have an ORDER BY clause. That ORDER BY clause will apply across all elements of
the compound. If the right-most element of a compound SELECT is a VALUES clause,
then no ORDER BY clause is allowed on that statement.
记录行首先按照ORDER BY列表中最左边的表达式计算结果进行排序,然后再按照左边第二个表达式来计算排序。两行记录如果ORDER BY的所有表达式计算结果都相同,那么最后返回的顺序将是不确定的。每个ORDER BY表达式后面都可以跟一个ASC(先返回较小值)或者DESC(先返回较大值)关键词。如果既没有指定ASC也没有指定DESC,记录行会默认按照升序(先返回较小值)返回。
Rows are first sorted based on the results of
evaluating the left-most expression in the ORDER BY list, then ties are broken
by evaluating the second left-most expression and so on. The order in which
two rows for which all ORDER BY expressions evaluate to equal values are
returned is undefined. Each ORDER BY expression may be optionally followed
by one of the keywords ASC (smaller values are returned first) or DESC (larger
values are returned first). If neither ASC or DESC are specified, rows
are sorted in ascending (smaller values first) order by default.
每个ORDER BY表达式都会按照如下方式来处理:
Each ORDER BY expression is processed as follows:
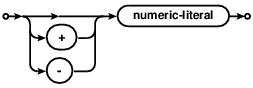
如果ORDER BY表达式是一个整数常数K,那么表达式会被当做是指定了结果集中的第K列(从左往右,从1开始为列编号)。
If the ORDER BY expression is a constant integer K then the expression is considered an alias for the K-th column of the result set (columns are numbered from left to right starting with 1).如果ORDER BY表达式是一个与输出结果的其中一列的别名相同的标示符,那么表达式表示指定了这一列。
If the ORDER BY expression is an identifier that corresponds to the alias of one of the output columns, then the expression is considered an alias for that column.否则,如果ORDER BY表达式是其他表达式,那么会使用这个表达式的计算结果来对输出行进行排序。如果是一个简单SELECT,那么ORDER BY 可以包含任意的表达式。可是,如果是一个复合SELECT,那么ORDER BY表达式不能是输出列的别名,必须和输出列表达式一致。(最后句似乎不对,#TODO#)
Otherwise, if the ORDER BY expression is any other expression, it is evaluated and the returned value used to order the output rows. If the SELECT statement is a simple SELECT, then an ORDER BY may contain any arbitrary expressions. However, if the SELECT is a compound SELECT, then ORDER BY expressions that are not aliases to output columns must be exactly the same as an expression used as an output column.
为了对记录行进行排序,数值的比较是按照比较表达式相同的方式。使用什么排序器来对两个文本值进行排序按照下面的方式决定的:
For the purposes of sorting rows, values are compared in the same way
as for comparison expressions. The collation sequence used to compare
two text values is determined as follows:
如果ORDER BY表达式使用COLLATE 操作符后缀指定了一个排序器,那么久使用这个指定的排序器。
If the ORDER BY expression is assigned a collation sequence using the postfix COLLATE operator, then the specified collation sequence is used.否则,如果ORDER BY表达式是一个表达式的别名,并且这个表达式使用COLLATE 操作符后缀分配了一个排序器,那么就使用分配给别名指向的表达式的排序器。
Otherwise, if the ORDER BY expression is an alias to an expression that has been assigned a collation sequence using the postfix COLLATE operator, then the collation sequence assigned to the aliased expression is used.否则,如果ORDER BY表达式是一个列或者一个列表达式别名,那么使用这一列的默认排序器。
Otherwise, if the ORDER BY expression is a column or an alias of an expression that is a column, then the default collation sequence for the column is used.否则,使用BINARY排序器。
Otherwise, the BINARY collation sequence is used.
在一个复合 SELECT语句中,所有的ORDER BY表达式都使用别名来处理复合的结果列。如果ORDER BY表达式不是一个整数别名,那么SQLite会搜索最左边的SELECT的结果列来匹配名字,否则,再搜索左边第二个SELECT,直到找到。如果在所有的组成SELECT结果列中没有找到匹配的名字,那么会引发一个错误。ORDER BY中的每个元素都死分别做匹配处理的,并且可能会从不同的SELECT语句中匹配到结果。
In a compound SELECT statement, all ORDER BY expressions are handled
as aliases for one of the result columns of the compound.
If an ORDER BY expression is not an integer alias, then SQLite searches
the left-most SELECT in the compound for a result column that matches either
the second or third rules above. If a match is found, the search stops and
the expression is handled as an alias for the result column that it has been
matched against. Otherwise, the next SELECT to the right is tried, and so on.
If no matching expression can be found in the result columns of any
constituent SELECT, it is an error. Each term of the ORDER BY clause is
processed separately and may be matched against result columns from different
SELECT statements in the compound.
LIMIT子句
The LIMIT clause
LIMIT子句是用来设置整个SELECT语句返回记录行数的上限。
The LIMIT clause is used to place an upper bound on the number of rows
returned by the entire SELECT statement.
在一个复合 SELECT语句中,只有最右边的简单 SELECT可以包含LIMIT子句。在一个复合 SELECT语句中,LIMIT适用于整个复合体,而不只是最后一个SELECT。如果最右边的简单 SELECT是一个VALUES 子句,那么则不能使用LIMIT子句。
In a compound SELECT, only the
last or right-most simple SELECT may contain a LIMIT clause.
In a compound SELECT,
the LIMIT clause applies to the entire compound, not just the final SELECT.
If the right-most simple SELECT is a VALUES clause then no LIMIT clause
is allowed.
任何标量表达式都可以适用于LIMIT子句,只要计算的结果是一个整数或者可以无损的转换到一个整数即可。如果表达式计算结果是个NULL或者是其它无法无损的转换为整数的值,那么会返回一个错误。如果LIMIT表达式计算返回一个负数,那么表示对返回结果行数上限没有限制。否则,SELECT只会返回结果集中的前N行记录,N是LIMIT计算出来的。或者,如果SELECT语句在没有LIMIT子句的情况下返回少于N条记录,那么整个结果集都会返回。
Any scalar expression may be used in the
LIMIT clause, so long as it evaluates to an integer or a value that can be
losslessly converted to an integer. If the expression evaluates to a NULL
value or any other value that cannot be losslessly converted to an integer, an
error is returned. If the LIMIT expression evaluates to a negative value,
then there is no upper bound on the number of rows returned. Otherwise, the
SELECT returns the first N rows of its result set only, where N is the value
that the LIMIT expression evaluates to. Or, if the SELECT statement would
return less than N rows without a LIMIT clause, then the entire result set is
returned.
LIMIT子句表达式可以选择附加一个可选的OFFSET子句,OFFSET子句表达式计算结果也必须是一个整数,或者可以无损的转换成整数。如果一个表达式包含一个OFFSET子句,那么SELECT子句返回结果的前M行会被忽略掉,后续的N行会返回,M和N是OFFSET和LIMIT子句分别计算得出的。或者,如果一个SELECT不使用LIMIT子句返回的结果行少于M+N行,那么前M行会被跳过,剩下的行(如果还有)会返回。如果OFFSET子句计算结果是个负数,那么结果和计算出零效果是一样的。
The expression attached to the optional OFFSET clause that may follow a
LIMIT clause must also evaluate to an integer, or a value that can be
losslessly converted to an integer. If an expression has an OFFSET clause,
then the first M rows are omitted from the result set returned by the SELECT
statement and the next N rows are returned, where M and N are the values that
the OFFSET and LIMIT clauses evaluate to, respectively. Or, if the SELECT
would return less than M+N rows if it did not have a LIMIT clause, then the
first M rows are skipped and the remaining rows (if any) are returned. If the
OFFSET clause evaluates to a negative value, the results are the same as if it
had evaluated to zero.
LIMIT子句可以指定逗号分隔的两个标量表达式,来替代单独的OFFSET子句。这种情况下,第一个表达式会当做OFFSET表达式使用,第二个表达式会当做LIMIT表达式。如果第一个参数是LIMIT表达式,第二个参数是OFFSET表达式,这样是反直觉的。所以有意翻转了OFFSET和LIMIT的位置——并且尽可能的兼容其他SQL数据库系统。不管怎样,为了避免混淆,程序员应该尽量使用LIMIT子句加OFFSET关键字,而避免使用LIMIT和逗号分隔的OFFSET。
Instead of a separate OFFSET clause, the LIMIT clause may specify two
scalar expressions separated by a comma. In this case, the first expression
is used as the OFFSET expression and the second as the LIMIT expression.
This is counter-intuitive, as when using the OFFSET clause the second of
the two expressions is the OFFSET and the first the LIMIT.
This reversal of the offset and limit is intentional
- it maximizes compatibility with other SQL database systems.
However, to avoid confusion, programmers are strongly encouraged to use
the form of the LIMIT clause that uses the "OFFSET" keyword and avoid
using a LIMIT clause with a comma-separated offset.
VALUES子句
The VALUES clause
"VALUES(expr-list)"短语的含义与"SELECT expr-list"是一样的。"VALUES(expr-list-1),...,(expr-list-N)"与 "SELECT expr-list-1 UNION ALL ... UNION ALL
SELECT expr-list-N"含义是相同的。使用二者都是一样的。两个格式都产生相同的结果,使用同样多的内存和处理时间。
The phrase "VALUES(expr-list)" means the same thing
as "SELECT expr-list". The phrase
"VALUES(expr-list-1),...,(expr-list-N)" means the same
thing as "SELECT expr-list-1 UNION ALL ... UNION ALL
SELECT expr-list-N". There is no advantage to using one form
over the other. Both forms yield the same result and both forms use
the same amount of memory and processing time.
这里有一些语法图上没有展示的VALUE子句使用限制。
There are some restrictions on the use of a VALUES clause that are
not shown on the syntax diagrams:
一个VALUES子句不能附加ORDER BY 或者 LIMIT子句。
A VALUES clause cannot be followed by ORDER BY or LIMIT.在一个简单 SELECT语句中VALUES子句无法和WITH子句一起使用。
A VALUES clause cannot be used together with a WITH clause in a simple SELECT.
WITH子句
The WITH Clause
SELECT语句有一个可选的WITH 子句前缀,这可以在SELECT语句中为用户定义一个或多个通用表表达式。
SELECT statements may be optionally preceded by a single
WITH clause that defines one or more common table expressions
for use within the SELECT statement.